Xây dựng và khai thác Kho Ngữ liệu Song ngữ Anh-Việt (*)
1. TỔNG QUAN
Trong việc nghiên cứu, giảng dạy ngôn ngữ, ta cần thống kê, so sánh, đối chiếu để tìm ra các quy luật của ngôn ngữ, quy luật chuyển ngữ, các điểm tương đồng và dị biệt ở các bình diện khác nhau, các cấp độ khác nhau giữa các ngôn ngữ. Nhưng để thống kê, so sánh, đối chiếu như trên, ta cần phải có cứ liệu của các ngôn ngữ mà ta đang cần so sánh, ta gọi đó là “ngữ liệu” (corpus). Ngữ liệu ở đây được hiểu là tập hợp văn bản đơn ngữ, đa ngữ hay song ngữ (gồm các cặp văn bản đã được dịch thủ công, dịch tương ứng 1-1 về mặt ngữ nghĩa) và phù hợp với lĩnh vực, thể loại, niên đại mà ta cần nghiên cứu. Ngoài phần Tổng quan và Kết luận, nghiên cứu này gồm các nội dung chính sau:
– Giới thiệu kho ngữ liệu song ngữ Anh – Việt.
– Xử lý kho ngữ liệu song ngữ Anh – Việt.
– Khai thác kho ngữ liệu song ngữ Anh – Việt.
2. GIỚI THIỆU KHO NGỮ LIỆU SONG NGỮ ANH – VIỆT
Trong nghiên cứu này, chúng tôi sử dụng ngữ liệu song song của 2 ngôn ngữ (gọi tắt là ngữ liệu song ngữ) và cụ thể là ngữ liệu song ngữ giữa tiếng Anh và tiếng Việt (gọi tắt là ngữ liệu song ngữ Anh-Việt). Trong ngữ liệu song ngữ, các bản dịch tương ứng của mỗi ngôn ngữ phải được đặt song song với nhau hay còn được gọi là gióng hàng với nhau (alignment).

Hình 1. Ví dụ gióng hàng ở mức đoạn.
Mức độ gióng hàng này có thể ở cấp độ văn bản (text alignment), nghĩa là từng văn bản trong ngôn ngữ nguồn được gióng (liên kết) với văn bản dịch tương ứng trong ngôn ngữ đích. Tương tự cho cấp độ đoạn (paragraph alignment), cấp độ câu (sentence alignment), cấp độ ngữ (phrase alignment) và sâu nhất là cấp độ từ (word alignment). Hình 1 là một ví dụ về gióng hàng ở cấp độ đoạn. Trong nghiên cứu này, chúng tôi đi sâu tới cấp độ gióng hàng từ (hình 2) để chúng ta có thể thu được nhiều nhất thông tin đối sánh giữa 2 ngôn ngữ.
Các ngữ liệu thu thập được sẽ chưa có chú thích thông tin ngôn ngữ (ngữ liệu thô). Trong nghiên cứu này, chúng tôi xây dựng ngữ liệu có chú thích nhằm sau này có thể khai thác được nhiều tri thức ngôn ngữ hơn. Thông tin ngôn ngữ được chú thích (hay còn gọi là nhãn ngôn ngữ) có thể là thông tin về bình diện hình thái, ngữ pháp và ngữ nghĩa của các đơn vị ngôn ngữ như từ, ngữ, câu. Trong nghiên cứu này, bước đầu, chúng tôi chỉ mới gán nhãn hình thái, nhãn ngữ pháp và nhãn ngữ nghĩa cho đơn vị từ. Nhãn hình thái từ ở đây chính là nhãn ranh giới từ. Nhãn ngữ pháp từ ở đây bao gồm các nhãn phân loại căn cứ theo mặt ngữ pháp của từ (hay còn gọi là từ pháp), cụ thể bao gồm hai phạm trù ngữ pháp của từ: phạm trù phân loại từ và phạm trù ngữ pháp biến đổi từ.
Khác với nhãn hình thái và ngữ pháp (đơn giản và dễ thống nhất với nhau), nhãn ngữ nghĩa hiện còn nhiều tranh cãi về cách phân loại. Qua khảo sát ý nghĩa từ vựng của mỗi thực từ, ta thấy nói chung mỗi từ có thể mang nhiều nghĩa từ vựng khác nhau, nhưng trong một ngữ cảnh cụ thể, chúng sẽ mang một nghĩa nhất định nào đó. Chẳng hạn, danh từ “bank” trong tiếng Anh có thể là “ngân hàng”, “kho lưu trữ”, “bờ sông”, “dãy”, …; danh từ “đường” trong tiếng Việt có thể có nghĩa là “đường ăn” (sugar) hay “đường đi” (street), … Để dễ phân biệt các nghĩa từ vựng khác nhau, các nhà ngữ nghĩa học, từ vựng học và tâm lý học – ngôn ngữ đã phân chia toàn bộ các ý nghĩa từ vựng có thể có thành hệ thống các ý niệm (cây ý niệm) và mỗi ý niệm như vậy được coi như là một lớp ngữ nghĩa hay nhãn ngữ nghĩa của từ. Đến nay, đã có một số cách phân lớp ngữ nghĩa cho tiếng Anh [2], như: LLOCE (Longman Lexicon of Contemporary English) gồm 2500 lớp, WordNet (khoảng 110.000 lớp), CoreLex (126 lớp), … Ví dụ, theo hệ thống CoreLex, các nghĩa tương ứng của danh từ “bank” sẽ là: “ngân hàng” thuộc về ý niệm “công trình nhân tạo” (nhãn ART); “bờ sông” sẽ thuộc về ý niệm “công trình thiên tạo” (nhãn NAT); “dãy” sẽ thuộc về ý niệm “sự sắp xếp tổ chức” (nhãn GRP). Tương tự cho danh từ “đường” trong tiếng Việt, nghĩa “đường ăn” sẽ được xếp vào ý niệm “hóa chất” (nhãn CHM); còn nghĩa “đường đi” sẽ được xếp vào ý niệm “không gian” (nhãn SPA); …
Ngữ liệu song ngữ thô (chưa qua xử lý) có thể được xây dựng bằng 3 cách chính: (1) Thu thập tự động từ các website song ngữ (2) Thu thập từ các ấn phẩm song ngữ (dạng điện tử) (3) Dịch thủ công, dịch song song 1-1 theo hướng dẫn (guideline) từ các văn bản nguồn có chất lượng và đúng lĩnh vực, niên đại. Cách (1) nhanh, chi phí thấp, số lượng lớn, chất lượng thấp (vì thường không được dịch song song 1-1), không phù hợp lĩnh vực và chưa gióng hàng ở mức nào. Cách (2) chi phí thấp, số lượng ít, chất lượng trung bình và chưa gióng hàng câu. Cách (3) chất lượng cao, lĩnh vực phù hợp, đã gióng hàng câu, nhưng chi phí cao. Trong nghiên cứu này, ngữ liệu song ngữ Anh-Việt được trích một phần từ kho ngữ liệu song ngữ EVC (phần mềm [1]) do các nhà nghiên cứu của Trung tâm Ngôn ngữ học Tính toán của Trường ĐH Khoa học Tự nhiên – Tp.HCM xây dựng (bằng cách 2 và 3) và đã công bố ở công trình [1].
3. XỬ LÝ NGỮ LIỆU SONG NGỮ ANH-VIỆT
Tùy theo cách thức xây dựng ngữ liệu song ngữ mà ta có các công đoạn xử lý khác nhau. Nếu ngữ liệu được thu thập từ website song ngữ, ta phải gióng hàng văn bản, rồi sau đó gióng hàng ở mức câu (có thể sử dụng công cụ phần mềm [2]). Nếu ngữ liệu thu thập từ ấn phẩm song ngữ thì chỉ cần gióng hàng câu. Ta có kết quả như minh họa bên dưới (Lưu ý: cần phải chuẩn hóa ngữ liệu thành dạng text-only và mã utf-8 trước khi sử dụng các công cụ trên):
* Helicopters can rise straight up into the air and can go straight down.
+ Máy bay trực thăng có thể lên thẳng trên không và đáp thẳng xuống đất.
* They can stand still in the air.
+ Chúng có thể đứng yên trên không.
* Helicopters do not have wings.
+ Máy bay trực thăng không có cánh.
Để gióng hàng tự động ở mức từ (word alignment), ta có thể sử dụng công cụ GIZA++ [3] và độ chính xác của công cụ này tùy thuộc vào khối lượng và chất lượng ngữ liệu (càng nhiều câu song song 1-1 thì các mối nối càng chính xác hơn). Do có sự khác biệt về loại hình ngôn ngữ giữa tiếng Anh (biến hình) và tiếng Việt (đơn lập), nên ranh giới từ giữa 2 ngôn ngữ là khác nhau. Vì vậy, để có kết quả gióng hàng từ tốt, chúng ta nên phân đoạn từ (word segmentation) tiếng Việt (có thể sử dụng công cụ [2]) trước khi thực hiện việc gióng hàng từ (xin xem kết quả như hình 2).
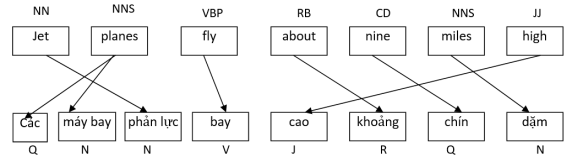 Hình 2. Cặp câu đã phân đoạn từ, gióng hàng từ và gán nhãn từ loại.
Hình 2. Cặp câu đã phân đoạn từ, gióng hàng từ và gán nhãn từ loại.
Ngữ liệu song ngữ sau khi được phân đoạn từ và gióng hàng từ, có thể được gán thêm các thông tin ngôn ngữ khác, như: từ loại (nhãn từ pháp) và ngữ nghĩa. Trong nghiên cứu này, chúng tôi đã sử dụng công cụ [2] để gán nhãn từ loại cho tiếng Việt và công cụ Stanford POS tagger [4] để gán nhãn từ loại cho tiếng Anh. Chúng tôi còn sử dụng công cụ [2] để gán nhãn ngữ nghĩa cho các thực từ trong song ngữ Anh – Việt dựa trên sự ràng buộc về ngữ nghĩa giữa các cặp từ/cụm từ tương ứng (nếu là dịch 1-1 thì cả hai phải cùng thuộc một lớp ngữ nghĩa) như sau:
Theo bộ nhãn LLOCE, khi ta xét từ “plane” và “fly” tương ứng với từ “máy bay” và “bay” trong cặp câu nói trên, ta thấy: “plane” là danh từ, sẽ thuộc các lớp J41 (không gian phẳng) và M180 (phương tiện hàng không), còn nếu “plane” là động từ sẽ thuộc các lớp khác. Tương tự cho từ “fly”, trong trường hợp này là động từ, sẽ thuộc lớp M19 (hành động bay). Tương ứng trong tiếng Việt, danh từ “máy bay” chỉ thuộc lớp M180, còn động từ “bay” thuộc lớp M19 và L47 (bay hơi/bay màu). Do nguyên lý chia sẻ cùng lớp ngữ nghĩa, ta xác định được “plane” và “máy bay” có nhãn ngữ nghĩa là M180 và “fly” và “bay” có cùng nhãn ngữ nghĩa là M19.
Do sự khác biệt về loại hình ngôn ngữ, loại hình văn hóa, nên sự nhập nhằng giữa 2 ngôn ngữ khác nhau thường là khác nhau. Nếu khi giao nhau (phép AND), giữa 2 tập lớp của 2 từ mà kết quả lớn hơn 1, lúc đó chương trình dùng thêm một số thông tin khác để chọn nhãn hợp lý nhất. Tất nhiên các kết quả xử lý tự động trên không thể chính xác hoàn toàn và cũng cần sự hiệu đính thủ công. Về tiêu chí phân đoạn từ (hay còn gọi là nhận diện ranh giới từ) tiếng Việt và bộ nhãn từ loại và bộ nhãn ngữ nghĩa, chúng tôi kế thừa từ công trình số [2].
4. KHAI THÁC NGỮ LIỆU SONG NGỮ ANH-VIỆT
Từ kho EVC, chúng ta có thể khai thác để phục vụ cho rất nhiều bài toán ở các lĩnh vực khác nhau, như: thống kê ngôn ngữ, so sánh đối chiếu ngôn ngữ để phục vụ cho việc nghiên cứu, giảng dạy ngôn ngữ; phát hiện quy luật ngôn ngữ,… Kho ngữ liệu càng lớn và được gán nhiều thông tin ngôn ngữ thì hiệu quả của việc khai thác càng lớn. Dưới đây là một số ví dụ khai thác EVC nhằm phục vụ giảng dạy ngôn ngữ:
4.1. Thống kê ngôn ngữ
4.1.1. Thống kê theo hình thái từ:
Do đặc thù của tiếng Việt, nên khi chúng ta sử dụng các công cụ tìm kiếm, thống kê ngôn ngữ của tiếng Anh, chúng ta sẽ không thể xác định đúng được hình thái của chuỗi đang tìm (vì chúng xem tiếng là từ). Còn trong ngữ liệu EVC, do có gán nhãn hình thái từ, nên việc tìm kiếm tiếng Việt sẽ hiệu quả hơn. Ví dụ ta muốn tìm từ “tin”: máy sẽ tìm ra từ “tin” nằm độc lập (như: “tin điều đó…”, “tin mới nhận”), hoặc từ “tin” trong ngữ: “nhắn tin”, “tin sốt dẻo”, …; chứ máy không bị nhầm lẫn với hình vị “tin” trong các từ “tin mừng”, “tin tức”, “thông tin” hay á-hình vị “tin” trong “căn-tin”, …Tương tự, khi tìm từ “quan tài”, máy sẽ không nhầm với cụm “quan tài” trong câu “một ông quan tài giỏi”. Tương tự, chúng ta có thể tìm từ tiếng Anh chính xác hoặc tất cả các biến cách (inflection) của nó, như: từ “display”, “displays”, “displayed” hay “displaying”.
4.1.2. Thống kê theo ngữ pháp từ:
Chúng ta có thể tìm kiếm từ theo từ loại của nó, ví dụ: tìm động từ “tin”: máy sẽ tìm ra đúng động từ “tin” nằm độc lập trong các trường hợp như: “chúng ta tin rằng …”; hoặc tìm danh từ “tin” trong các ngữ: “nhắn tin”, “tin sốt dẻo”, …;
Tương tự cho việc tìm động từ “display”: máy sẽ tìm ra từ đó trong “display information” (cũng như các biến cách động từ của nó, như: “displayed information”, “displays information”, “displaying information”); hoặc chỉ tìm danh từ “display” trong “a new display” (cũng như các biến cách danh từ của nó, như: “many new displays” ).
Với thông tin về tiểu từ loại và ngữ pháp biến đổi từ, kho ngữ liệu EVC có thể đáp ứng được các yêu cầu khai thác chi tiết hơn, như: tìm từ tiếng Việt theo tiểu từ loại (động từ nội động; ngoại động; danh từ đơn thể, danh từ tổng thể, danh từ khối, …); tìm từ tiếng Anh theo tiểu từ loại và ngữ pháp biến đổi từ (như: chỉ tìm những động từ ngôi 3 số ít, danh từ số nhiều, …); Ngoài ra, chúng ta cũng có thể thống kê xem trong kho ngữ liệu của chúng ta: mỗi từ loại/tiểu từ loại có bao nhiêu từ, bao nhiêu lượt từ cho mỗi ngôn ngữ.
4.1.3. Thống kê theo ngữ nghĩa từ:
Ta có thể thống kê riêng danh từ “đường” (sugar) trong ngữ liệu tiếng Việt, tránh bị nhầm lẫn với các danh từ “đường” khác (như: street, line, …) bằng cách tìm danh từ “đường” với nhãn ngữ nghĩa là CHM (chemicals). Tương tự, ta có thể tìm tự động rất nhanh tất cả các từ theo một chủ đề cụ thể nào đó mà các phương pháp tìm kiếm truyền thống trước đây không thể thực hiện được. Chẳng hạn ta muốn tìm tất cả các từ nói về truyền thông (COM) trong ngữ liệu (như hình 3). Tương tự cho các yêu cầu tìm kiếm danh từ về thức ăn (dùng nhãn E1), bộ phận cơ thể con người (nhãn C3), …
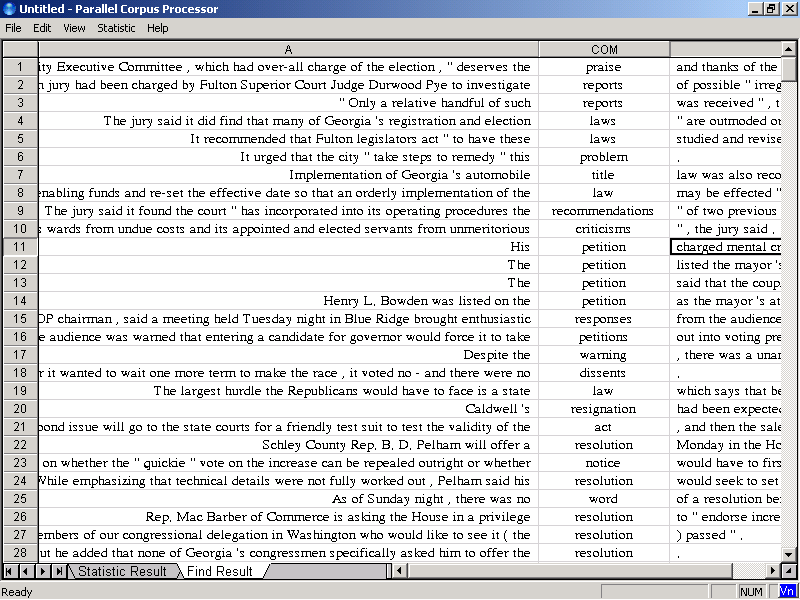
Hình 3. Tìm các từ về “truyền thông” (COMmunication).
Ngoài những thống kê chính nêu trên, chúng ta còn có thể tìm kiếm, thống kê theo nhiều thông số khác và có thể kết hợp các tham số đó với nhau. Ví dụ: thống kê về chiều dài câu, tần suất sử dụng động từ/danh từ, tần suất sử dụng một từ cụ thể hay các từ cùng lớp ngữ nghĩa. Kết quả thống kê này có thể được dùng để: xây dựng vốn từ cơ bản, so sánh độ tương đồng văn bản, truy tìm tác giả khuyết danh, khám phá phong cách của tác giả, đoán nhận trọng tâm tác phẩm, kiểm nghiệm giả thuyết trong ngôn ngữ, …
Một điều đặc biệt là tất cả các kết quả tìm kiếm trong tiếng Việt sẽ có câu tiếng Anh hiển thị song song bên dưới và đánh dấu từ/cụm từ tiếng Anh tương ứng với từ/cụm từ tiếng Việt đó và ngược lại (vì EVC của chúng ta đã được gióng hàng câu và gióng hàng từ). Đây là điều vô cùng cần thiết khi so sánh, đối chiếu giữa 2 ngôn ngữ.
4.2. So sánh đối chiếu ngôn ngữ
Kho EVC sẽ giúp chúng ta so sánh đối chiếu các điểm tương đồng và dị biệt, như:
4.2.1. So sánh Anh – Việt về sự từ vựng hóa:
Quan sát các mối nối từ tương ứng trong EVC (hình 2), ta sẽ thấy sự khác biệt về từ vựng hóa giữa 2 ngôn ngữ: có khái niệm được từ vựng hóa trong ngôn ngữ này nhưng lại không được từ vựng hóa trong ngôn ngữ kia và ngược lại. Ví dụ: “cow” để chỉ “bò cái” được xem là từ trong tiếng Anh nhưng lại không là từ trong tiếng Việt (lúc này mối nối gióng hàng từ không còn là 1-1 mà là 1-n hay m-1).
4.2.2. So sánh Anh – Việt về từ loại:
Quan sát nhãn từ loại và mối nối từ trong EVC (hình 2), ta sẽ thấy có khi trong tiếng Anh dùng danh hóa (nominalization) còn tiếng Việt tương ứng lại dùng động hóa (verbalization). Có nghĩa là đôi khi 2 bên không cùng từ loại. Ví dụ: trong tiếng Anh, người ta nói “thank you for your attention”, tiếng Việt là: “cám ơn các bạn đã chú ý”.
4.2.3. So sánh Anh – Việt về trật tự từ:
Do EVC đã được gióng hàng từ, nên khi quan sát các mối nối (hình 2), ta sẽ thấy có sự thay đổi về trật tự từ giữa 2 ngôn ngữ (các mối nối bị chéo nhau).
4.2.4. So sánh Anh – Việt theo các khía cạnh khác:
Ngoài các so sánh trên, ta còn có thể khai thác EVC để trợ giúp việc so sánh Anh-Việt theo các khía cạnh khác như: so sánh từ tình thái, phương tiện biểu đạt phạm trù thời gian, không gian giữa tiếng Anh và tiếng Việt: nhờ vào mối nối từ Anh-Việt và nhãn ngữ nghĩa của các từ tiếng Anh, ta biết được từ nào thuộc về phạm trù thời gian (TME) và từ nào thuộc về phạm trù không gian (SPA) để so sánh tự động. Ví dụ: về phạm trù không gian, ta thấy người Anh dùng giới từ “in“ (trong) khi nói “in the sky” (dịch sát nghĩa là “trong trời”), còn người Việt mình sẽ nói “trên trời”; so sánh cách xưng hô giữa tiếng Anh và tiếng Việt: cũng nhờ vào mối nối từ Anh-Việt và nhãn từ pháp, ta biết từ nào là từ chỉ về cách xưng hô (PRO) để ta so sánh tự động.
4.3. Khai thác phục vụ giảng dạy ngoại ngữ
Một trong những mục đích chính của việc xây dựng kho ngữ liệu song ngữ là để khai thác phục vụ cho việc giảng dạy ngoại ngữ [3], cụ thể ở đây là dạy tiếng Anh cho người Việt và tiếng Việt cho người nước ngoài thông qua các so sánh trực quan như:
4.3.1. Khảo sát cách dùng từ qua chuỗi đồng hiện (concordance):
Một từ có thể có nhiều nghĩa khác nhau, nghĩa cụ thể của từ phụ thuộc vào ngữ cảnh của từ (context). Chính vì vậy, mà khi xem xét nghĩa/cách dùng của một từ nào đó, ta cần xem xét ngữ cảnh tương ứng của nó. Ví dụ: cách chọn từ tiếng Anh phù hợp khi dịch từ “xảy ra”. Qua quan sát trong EVC, ta sẽ tự nghiệm ra khi nào dùng “occur” (như: lỗi máy tính), “happen” (tai nạn) hay “take place” (sự kiện).
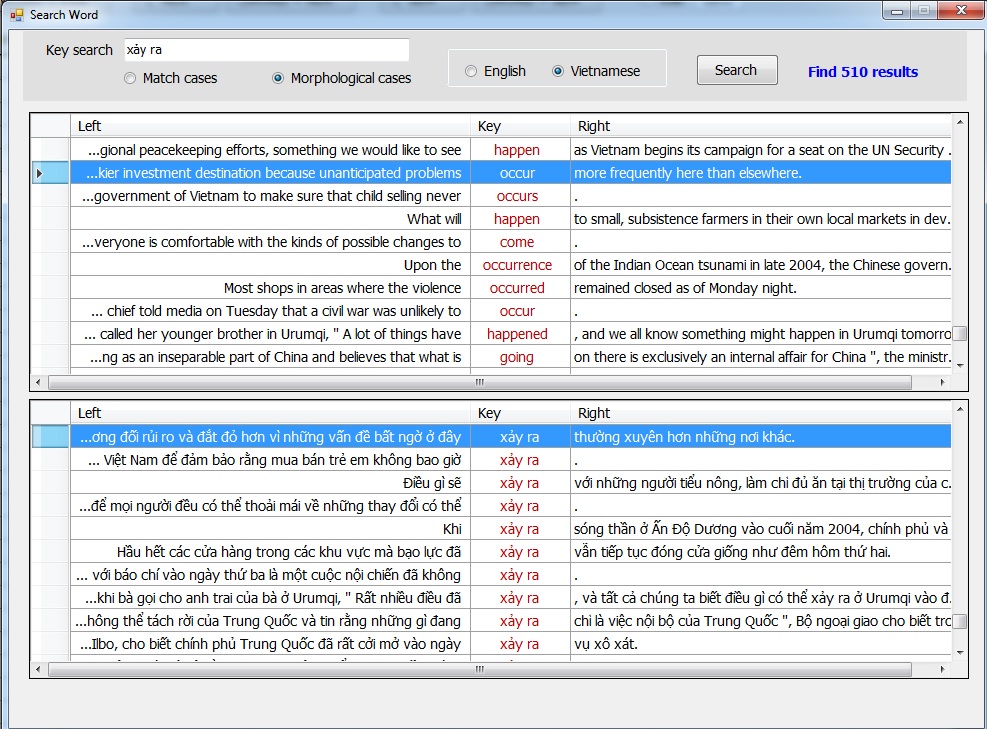
Hình 4. So sánh cách dịch từ “xảy ra” trong tiếng Anh.
Với kho ngữ liệu lớn, được lấy mẫu hợp lý, hầu hết các hiện tượng ngôn sẽ được phản ánh chính xác, sinh động và cập nhật hơn so với từ điển. Ví dụ: Trong các từ điển, từ “fond of” được ghi là “nâng niu, vuốt ve” (mang nội dung tích cực), nhưng qua thống kê trên ngữ liệu thực tế BNC [3] (British National Corpus), người ta thấy hơn 60% từ này được dùng với nghĩa tiêu cực (nghĩa là “quấy rối tình dục” !).
4.3.2. Khảo sát chuỗi ngôn từ (collocation):
Trong thực tế, có một số từ người bản ngữ dùng chung với nhau, chẳng hạn: đỏ lòm/lè, tím ngắt/lè; gà trống/đực, dê đực/trống; súc miệng/mồm, … ; big/heavy rain, pink/rosé wine, strongly/bitterly disappointed, ... Chính vì vậy, với EVC, qua việc khảo sát trực quan các chuỗi ngôn từ này, sẽ giúp người học ngoại ngữ biết cách dùng từ thích hợp trong ngữ cảnh thích hợp, biết được tính từ nào sẽ dùng với danh từ nào, động từ nào dùng với danh từ nào, trạng từ nào đi với động từ nào, …
4.3.3. Chuyển ngữ Anh – Việt cho một số cụm từ cố định:
Trong ngôn ngữ thường có các cụm từ có tính thành ngữ cao và khi chuyển ngữ ta không thể dịch theo kiểu trực tiếp từng từ một (word-by-word). Để chuyển ngữ được các cụm từ được chính xác, ta có thể dùng song ngữ để so sánh đối chiếu trên phạm vi rộng và rút trích tự động danh sách các cụm từ đó để giảm thiểu chi phí dịch thủ công sau này.
4.4. ỨNG DỤNG EVC TRONG CÔNG TÁC DỊCH THUẬT ANH-VIỆT
Với kho song ngữ Anh-Việt EVC, chúng ta có thể sử dụng một số công nghệ hỗ trợ dịch thuật gần đây để giảm thiểu đáng kể công sức dịch thuật văn bản:
4.4.1. DỊCH MÁY THỐNG KÊ (STATISTICAL MACHINE TRANSLATION)
Theo công nghệ dịch máy thống kê (SMT), máy sẽ “học” tự động (machine learning) các quy tắc chuyển ngữ từ kho ngữ liệu song ngữ lớn đã gióng hàng ở mức câu (sentence alignment). Đây là công nghệ dịch tự động phổ biến nhất hiện nay (Google Translate, Bing Translator, … đang sử dụng công nghệ này). Với công nghệ dịch tự động, chúng ta xem như bản dịch của máy là bản dịch thô và chúng ta chỉ chỉnh sửa những lỗi sai của bản dịch thô đó mà không phải dịch từ đầu. Điều này giảm đáng kể thời gian nhập liệu (câu dịch) và thời gian tra từ điển. Nếu ngữ liệu song ngữ chúng ta lớn và cùng lĩnh vực (không phải là văn chương) thì kết quả dịch thô của máy càng chính xác [2].
4.4.2. DỊCH DỰA TRÊN BỘ NHỚ (TRANSLATION MEMORY)
Trong các công cụ phần mềm dịch thuật với sự trợ giúp của máy tính (CAT: Computer-Aided Translation), máy tính sẽ phân tích tự động văn bản nguồn thành các “đoạn” (segment) và lưu trong bộ nhớ dưới dạng song ngữ (tức là có sự liên kết giữa “đoạn” nguồn với phần dịch tương ứng). “Đoạn” ở đây là thể là cụm từ, ngữ, mệnh đề hay câu. Để khi ta dịch văn bản mới, máy sẽ tự động tìm kiếm trong bộ nhớ những “đoạn” nào đã được dịch trước đó và máy sẽ xuất ra các kết quả đã dịch để người không phải dịch lại. Người chỉ dịch thủ công các phần chưa được dịch trước đó và máy sẽ lại tự cập nhật phần dịch thêm này để hệ thống sử dụng cho lần sau. Việc phân đoạn (segmentation) văn bản và tìm kiếm các đoạn được thực hiện theo các công cụ và giải thuật trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP: Natural Language Processing). Việc so sánh các “đoạn” có thể là so khớp hoàn toàn hoặc so khớp mờ (fuzzy) một cách “thông minh” (khi máy xét đến các biến thể về hình thái, ngữ pháp và ngữ nghĩa). Máy sẽ ưu tiên chọn “đoạn” dài nhất và chọn phần dịch tương ứng có xác suất cao nhất (vì có nhiều “đoạn” đã được dịch theo các cách khác nhau tùy theo ngữ cảnh) [3].
Với cách thức này, nếu chúng ta có kho ngữ liệu song ngữ lớn và có độ tương đồng cao (về từ vựng, thuật ngữ, cấu trúc, lĩnh vực, phong cách) với văn bản mới cần dịch (như: bản địa hóa các tài liệu hướng dẫn sử dụng, các hợp đồng, …), thì công sức dịch mới sẽ được giảm đáng kể.
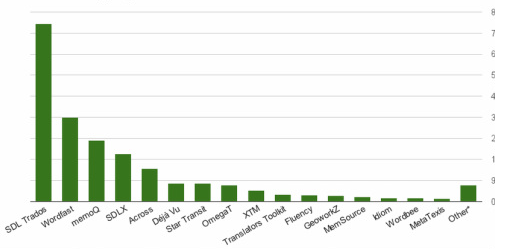
Hình 5. Mức độ phổ biến của các công cụ CAT hiện nay.
Các công cụ này còn có thể hỗ trợ các thao tác khác của người dịch, như: giữ nguyên định dạng tập tin nguồn, tra cứu thuật ngữ, kiểm lỗi chính tả, kiểm tra tính nhất quán việc dịch các thuật ngữ, quản lý dự án dịch với nhiều cộng tác viên từ xa, … Tuy nhiên, các công cụ này hiện nay chủ yếu hoạt động hiệu quả khi phân tích tiếng Anh (và một số tiếng thông dụng ở Châu Âu), còn khi phân tích tiếng Việt sẽ có nhiều hạn chế do đặc thù ngôn ngữ tiếng Việt, vì vậy, cần có sự can thiệp (tiền xử lý) vào ngữ liệu trước khi sử dụng hoặc phải sử dụng phần mềm CAT đặc thù cho tiếng Việt.
Qua phân tích các ứng dụng nói trên của song ngữ, ta thấy kho EVC của chúng ta có thể khai thác phục vụ cho cả hai mục đích: về lý thuyết (giảng dạy dịch thuật) lẫn thực hành (công tác dịch thuật). Vì vậy, chúng ta cần tăng cường số lượng (thu thập thêm nhiều văn bản song ngữ), chủng loại (nhiều lĩnh vực khác nhau) và xử lý sâu (gán nhãn ngôn ngữ); đồng thời xây dựng các công cụ chuyển đổi tự động định dạng từ EVC hiện nay sang định dạng của hệ SMT/CAT và ngược lại, để cả 2 bên (sinh viên và người dịch chuyên nghiệp) học hỏi/kế thừa được toàn bộ tri thức/kinh nghiệm dịch thuật từ hàng ngàn bản dịch, hàng triệu câu đã được dịch trước đây.
5. KẾT LUẬN
Ngữ liệu nói chung và ngữ liệu song ngữ Anh-Việt nói riêng sẽ giúp chúng ta rất nhiều trong vô vàn các ứng dụng khác nhau. Từ lĩnh vực Ngôn ngữ học so sánh đối chiếu, cho đến việc giảng dạy ngoại ngữ nói chung, môn biên dịch nói riêng, ngữ liệu song ngữ Anh-Việt sẽ giúp cho người học tự “nghiệm” ra các quy luật chuyển ngữ mà các cách tiếp cận truyền thống không thể bao quát hết được. Đặc biệt trong công tác dịch thuật chuyên nghiệp, kho ngữ liệu Anh – Việt này sẽ làm giảm đáng kể công sức dịch thuật thủ công. Nếu kho ngữ liệu này được tiếp tục cập nhật thì hiệu quả khai thác càng tăng gấp bội. Ngoài ra, cách thức này có thể áp dụng cho các cặp ngôn ngữ khác [4].
TÀI LIỆU THAM KHẢO
[1]. Dien Dinh, “Building an Annotated English-Vietnamese parallel Corpus”, MKS: A Journal of Southeast Asian Linguistics and Languages, Vol.35, pp.21-36, 2005.
[2]. Đinh Điền, “Xây dựng và khai thác ngữ liệu song ngữ Anh-Việt điện tử“, luận án tiến sĩ ngôn ngữ học so sánh, ĐH Khoa học Xã hội & Nhân văn, ĐHQG Tp.HCM, 3/2005.
[3] Lynne Bowker, Computer-Assisted Translation Technology: A Practical Introduction, University of Ottawa Press, 2002, ISBN 0-7766-0538-0.
[4] Phuoc T., Dien D. “A Novel Approach for Handling Unknown Word Problems in the Chinese-Vietnamese Machine Translation”, International Journal of Computational Linguistics and Chinese Language Processing (IJCLCLP), Vol.19, No.1, March 2014, pp.1-10, ISSN: 1027-376X.
PHẦN MỀM
[1]. http://www.clc.hcmus.edu.vn/wp-content/uploads/resources/Corpus/CLC_EVC.zip
[2]. http://www.clc.hcmus.edu.vn/wp-content/uploads/resources/Tools
[3]. http://www.statmt.org/moses/giza/GIZA++.html
[4]. http://nlp.stanford.edu/software/tagger.shtml
—————————————————————
(*) Nội dung bài viết này được trích từ công trình: Đinh Điền, Lý Ngọc Minh, “Ứng dụng Ngữ liệu Song ngữ Anh-Việt trong Giảng dạy Ngôn ngữ”, hội thảo Liên ngành NNH Ứng dụng & Giảng dạy Ngôn ngữ, 11/2015, Huế, tr.559-567.